The promise of clinical AI is compelling: a system that can answer any question about a patient's history, flag a drug interaction buried in a five-year-old note, or surface a missed follow-up from last quarter. But there's a fundamental tension in how most systems try to fulfill that promise—and it shows up at the worst possible time.
The Problem with Traditional RAG
Standard Retrieval-Augmented Generation (RAG) is the industry default. It works by converting your documents into vector embeddings, storing them in a search index, and retrieving the most semantically relevant chunks when a query arrives. It's fast and scalable—but it has a well-known Achilles heel: the chunk is never the whole story.
A single vector chunk might contain the phrase "penicillin allergy" without any surrounding context about when it was documented, by whom, or whether it was later updated. In most enterprise applications, that's an acceptable trade-off. In clinical environments, it is not.
Why "Cache Augmented Generation" Alone Isn't Enough Either
An alternative approach gaining traction is Cache Augmented Generation (CAG): pre-load the entire document corpus directly into the model's context window. No retrieval step. No lost chunks.
The appeal is obvious. But the math on clinical deployments breaks down quickly. A busy clinic can generate thousands of patient records, lab reports, imaging scans, and referral letters per year. Pre-loading all of that for every query would be astronomically expensive, brutally slow, and would hit context limits before even reaching medium-scale practices.
The ARAGS Path: Hybrid CAG
We designed Hybrid Cache Augmented Generation (Hybrid CAG) to take the best from both approaches while eliminating their respective failure modes.
The core insight: the sovereign GCS bucket
(arags-original-{client_id}) is itself a cache.
Every original document—every PDF, every DICOM file, every intake
form—is archived there in immutable form the moment it enters the
Clinical Fortress Gate. The AI doesn't need to hold the entire corpus
in memory. The infrastructure already does.
The Dual-Tier Retrieval Architecture
ARAGS executes every clinical query through a two-stage retrieval loop:
Tier 1 — Vector Scan (Speed Layer)
The system performs a high-speed semantic search against the client's
private Vertex AI Search data store. This surfaces relevant
source_uri references and contextual snippets in
milliseconds—enough to answer most queries with confidence.
Tier 2 — Ecosystem Referencing (Depth Layer)
If the vector snippet is insufficient—if the AI needs the full
radiology report, the original signed consent, or the raw lab
panel—it invokes the cag_fetch tool. This reads the
immutable original file directly from the
Originals Cache in GCS.
The result: the AI surrounds the data rather than containing it. The ecosystem provides the "eyes" to look into the cache on demand, rather than forcing the model to carry the entire knowledge base in its context window.
Why This Matters for Clinical Fidelity
Consider a common clinical scenario: a clinician asks, "What was the outcome of Maria's MRI from last October?"
With a standard RAG system, the answer depends entirely on whether the relevant text chunk was captured with sufficient context during indexing. Common failure modes include truncated reports, missed follow-up notes, and absent radiologist addenda.
With Hybrid CAG:
- Tier 1 identifies the source document instantly via semantic search.
- Tier 2 fetches the complete, immutable original directly from the vault—including every page, every annotation, and every amendment.
The AI reasons over the full source, not a fragment of it.
Sovereignty by Design
One of the non-negotiable constraints of clinical AI is data residency. Patient records cannot traverse jurisdictional boundaries or pass through third-party indexing services.
Hybrid CAG satisfies this by design. The Originals Cache is a
jurisdiction-locked GCS bucket
(arags-original-{client_id}). Fetches via
cag_fetch never leave the sovereign perimeter. The vector
store is a private, per-client Vertex AI Search data
store—not a shared index. No patient's data is ever
commingled with another clinic's records.
This is the core difference between ARAGS and generic document chatbots: our retrieval architecture was built for clinical accountability and sovereignty from the ground up, not retrofitted onto a general-purpose framework.
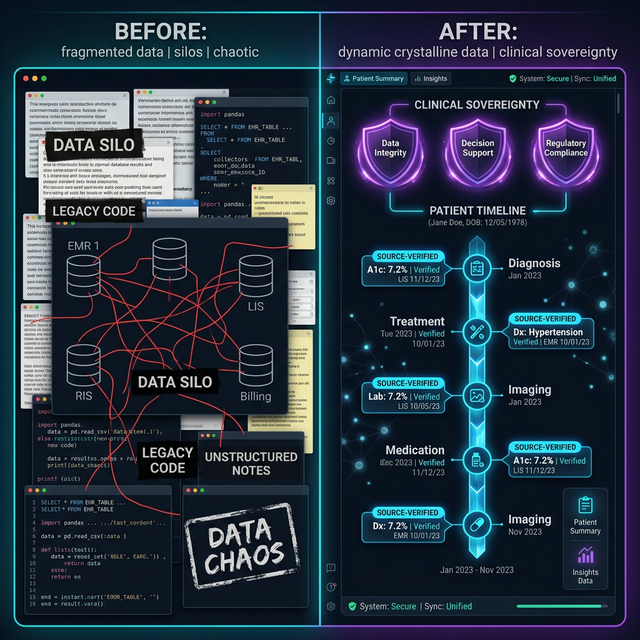
From Data Chaos to Clinical Clarity
The "wow" factor of Hybrid CAG isn't just the technical architecture—it's the elimination of Knowledge Debt. In traditional clinical workflows, valuable insights are trapped in unstructured silos, creating a "friction-first" experience for clinicians.
By treating the ecosystem as a persistent memory layer, we transition from scattered fragments to a high-fidelity Clinical OS. This architecture directly addresses the administrative crisis in Alberta's healthcare by:
- Eliminating Click-Heavy Latency: No more navigating static menus to verify a five-year-old diagnosis.
- Reducing Cognitive Overload: The AI synthesizes the entire relevant history on-demand, not just the highlights.
- Accelerating Diagnosis: Clinicians move from "searching for data" to "acting on intelligence" in seconds.
The Transformation: Before vs. After ARAGS
| Feature | Traditional RAG / Manual Workflow | ARAGS Hybrid CAG |
|---|---|---|
| Data Integrity | Fragmented chunks; risky summaries. | 100% Fidelity; direct original fetches. |
| Sovereignty | Shared or un-locked cloud storage. | Sovereign Silos; jurisdictionally resident. |
| Recall Consistency | Dependent on chunking quality. | Immutable Depth; reads the full source. |
| Clinician Effort | High "Click Debt" & search latency. | Zero-Training agentic orchestration. |
Scale Without Sacrifice
The Hybrid CAG model scales elegantly:
- Small clinics: Tier 1 alone handles most queries. The vault is small, fetches are fast.
- Multi-location practices: The vector layer scales to tens of thousands of documents. Tier 2 fetches are selective—only invoked when the snippet is genuinely insufficient.
- Enterprise deployments: The architecture remains constant. What changes is the size of the data store and vault, not the logic.
This means ARAGS can support a solo practitioner and a multi-site dental group on identical infrastructure, with identical guarantees. Audit trails, sovereignty, and retrieval fidelity don't degrade at scale.
By unifying agent-to-agent, agent-to-user, and agent-to-system logs into a single forensic timeline, Hybrid CAG provides clinicians with the ultimate safety net: absolute transparency in every retrieval decision.
What's Next
We're continuing to harden the cag_fetch tool with
additional compliance instrumentation—logging every direct vault access
in the Trilingual Audit Trail (A2A, A2UI, A2S) to
ensure full forensic traceability of every retrieval decision.
The goal is a system where a compliance auditor can answer, for any AI response ever generated: "Which documents did the model read? Were they current? Were they sovereign?"
At ARAGS, the answer to all three is always yes.
Want to see Hybrid CAG in action for your clinic? Request Beta Access.
We are redefining clinical memory—not just as a searchable database, but as a sovereign foundation for the future of autonomous healthcare.